
Real Late Starter
[PyTorch] 6. Loss & Optimizer 본문

1. Loss
※ Loss 란?
모델의예측이라벨과 얼마나 차이가 나는지를 측정합니다. 다르게 표현하면, 모델이 얼마나 부정확한지를 나타냅니다. 이 값을 판단하려면 모델에서 손실 함수를 정의해야 합니다. 예를 들어 선형 회귀 모형은 일반적으로평균 제곱 오차를, 로지스틱 회귀 모형은로그 손실을 손실 함수로 사용합니다.

위의 그림에서 Input(입력) = x, Output(출력) = y, Label(실제 정답) = d 이라고 가정했을 때.
우리는 데이터를 모델에 넣었을 때 Input과 Label를 가지고 있습니다. 모델을 통해서 나온 Output 값은 실제 값과 차이가 있을 수 있습니다. 따라서 y = W(weight)x + b(bias)로 y를 정의했을 때 실제 정답인 d - y의 차이가 Loss가 됩니다.
우리는 머신러닝 또는 딥러닝 모델을 통해 결과를 예측할 때 실제값과 차이가 없기를 바랍니다. 실제값과 차이가 없어야지 모델이 정확한 예측을한 것이기 때문입니다.
만약에 출력과 정답 차이가 0이 아니라면 모델은 완벽하게 예측하지 못한 것입니다. 하지만 차이가 없게 정확하게 예측하는 것은 불가능에 가까운 것이고 그렇게 나왔다고 하더라도 모델이 해당 overfitting(과적합)된 것인지 의심해봐야합니다.
- Loss 계산을 어떻게 하는가?
Loss는 우리가 해결해야될 문제의 유형에 따라서 Loss를 계산하는 법도 달라지게 됩니다.
| Type (문제의 유형) | 출력층에 쓰이는 활성화 함수 | Error Function(=Loss Function) |
| 회귀 문제 | 항등 사항 | 제곱 오차 (Squared Error) |
| 이진 분류 | Logistic Function | BCELoss(Binary Cross Entropy Loss) |
| 다중 클래스 분류 | Softmax Function | Cross Entropy |
1) Regression(회귀) 문제의 Loss Function
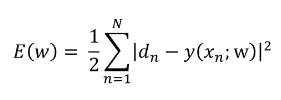
회귀 문제에서는 활성화 함수를 따로 쓰지 않습니다. Loss Function으로는 제곱 오차를 사용합니다. 그 이유는 계산이 간편하고 미분이 쉽기 때문이다.
제곱 손실(squared loss)
선형 회귀에 사용되는 손실 함수입니다. L2 손실이라고도 합니다. 이 함수는 라벨이 있는 예에 대한 모델의 예측 값과 라벨의 실제 값 차이의 제곱을 계산합니다. 이 손실 함수는 제곱을 구하므로 부정확한 예측에 더 큰 영향을 줍니다. 즉, 제곱 손실은 L1 손실보다 이상점에 민감하게 반응합니다.
2) Binary Classification(이진 분류) 문제의 Loss Function
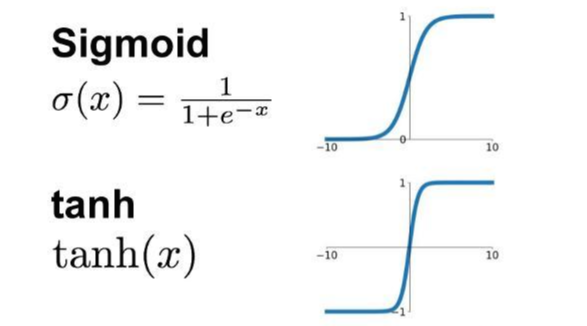
이진 분류 문제에서는 결과값이 0~1사이의 값으로 바뀌어야 하기 때문에 마지막 출력층 결과값을 바꿔주는 Activation Function을 사용해야한다. 따라서 Sigmoid, Tanh 같은 함수를 사용한다.
- Sigmoid function
로지스틱 또는 다항 회귀 출력(로그 확률)을 확률에 매핑하여 0~1 사이의 값을 반환하는 함수입니다.

3) Multi Classification(다중 분류) 문제의 Loss Function
다중 분류 문제에서는 활성화 함수로 Softmax Function을 사용합니다. 사용하는 이유는 출력의 합이 1이 되기 때문이다. 만약 출력이 10개가 나온다면 그 출력의 합이 1이다.
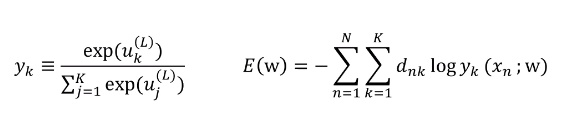
소프트맥스에서 나온 값을 크로스엔트로피 함수를 이용해서 Loss를 계산을 합니다.
PyTorch에는 수많은 Loss Function들이 있습니다. 아래 링크를 들어가보시면 다양한 Loss Function에 대한 설명을 볼 수 있습니다.
https://pytorch.org/docs/stable/nn.html#parameters
torch.nn — PyTorch master documentation
Shortcuts
pytorch.org
| L1loss | NLLLoss | KLDivLoss | MarginRankingLoss | SmoothL1Loss | CosineEmbeddingLoss |
| MSELoss | PoissonNLLoss | BCELoss | HingeEmbeddingLoss | SoftMarginLoss | MultiMarginLoss |
| CrossEntropyLoss | NLLLoss2d | BCEWtihLogitsLoss | MultiLabelMarginLoss | MultiLabelSoftMarginLoss | TripletMarginLoss |
2. Optimizer
Optimizer는 경사하강법 알고리즘의 구체적인 구현이라고 할 수 있습니다. 모델을 최적화하기 위해, Weight에 대한 Error(Loss)를 최대한 작게 만들기 위해서 Optimizer(최적화)기법을 사용합니다.
- Adadelta
- Adagrad
- Adam
- SparseAdam
- Adamax
- ASGD
- LBFGS
- RMSprop
- Rprop
- SGD
3. Loss Function과 Optimizer를 사용하여 네트워크를 구성해보기
이전에 CIFAR-10 데이터를 불러와 네트워크를 구성했던 것에 이어서 진행을 해보겠습니다.
Loss Function은 CrossEntropyLoss를 사용하고 Optimizer는 SGD를 사용합니다.
CrossEntrophLoss

SGD

선언은 다음과 같이 할 수 있습니다.
optim = torch.optim.SGD(Net.parameters(), lr=0.001, momentum=0)
Loss_func = nn.CrossEntropyLoss()4. Network Parameter Update
이번에는 네트워크를 구성하고 Loss function과 Optimizer를 사용하여 모델을 학습 시켜보겠습니다.
모델은 다음과 같이 구성합니다.
class my_network(nn.Module):
def __init__(self):
super(my_network, self).__init__()
self.conv1 = nn.Conv2d(3,64,5) # 3 채널을 받아서 64채널로 만들고
self.conv2 = nn.Conv2d(64,30,5) # 64채널을 받아서 30채널로 반환하고
self.fc1 = nn.Linear(30*5*5, 128) # 30채널에 5by5이미지를 Flatten 시켜 출력이 128개인 FC를 구성합니다.
self.fc2 = nn.Linear(128, 10) # FC를 128개에서 10개로 출력하는 것으로 구성합니다.
def forward(self,x):
x = F.relu(self.conv1(x), inplace = True) # 구성한 conv layer를 relu 함수에 넣고
x = F.max_pool2d(x, (2,2)) # pooling을 진행합니다.
x = F.relu(self.conv2(x), inplace = True)
x = F.max_pool2d(x,(2,2))
x = x.view(x.shape[0], -1) # view는 1차원의 벡터로 변환하는 기능입니다. x.shape[0]는 배치 사이즈와 같습니다.
x = F.relu(self.fc1(x), inplace = True) # FC 진행
x = F.relu(self.fc2(x), inplace = True)
return x생성한 모델을 GPU에 올립니다. Loss는 CrossEntropyLoss()를 사용하고
optimizer는 torch.optim.SGD()를 사용하고 learning rate는 0.001, momentum은 0.9로 주었습니다.


3번의 epoch의 학습결과 입니다.

Loss를 시각화해보면 상당히 튀는 것을 볼 수 있습니다. 네트워크가 얕고 정교한 네트워크가 아니기 때문에 Loss가 튀는 것으로 보입니다.
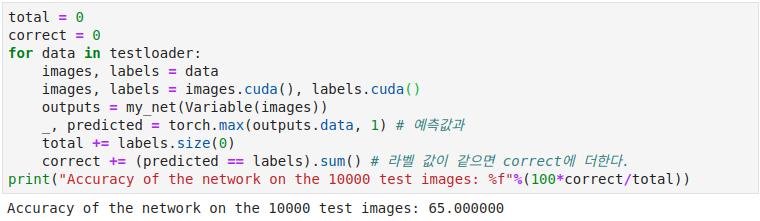
다음은 모델을 평가하는 코드입니다. 정확도가 65%가 나왔습니다.
이 포스트는 김군이(https://www.youtube.com/watch?v=KXiDzNai9tI&t=984s)님의 강의를 듣고 공부하며 정리한 내용을 올린 것입니다