
Real Late Starter
[PyTorch] LSTM을 활용한 COVID-19 해외유입확진자 수 예측 본문

근래에 가장 큰 이슈라고 할 수 있는 코로나 바이러스에 대한 프로젝트입니다. 국내에서는 2020년 초부터 국내확진자가 확인되기 시작해서 여러가지 집단감염 사태를 통해 확진자가 급증했습니다. 현재는 감염이 많이 줄고 사회적 거리두기에서 생활 속 거리두기로 변경되었는데요. 물론, 현 시점에서 이태원 클럽 집단 감염으로 인해 국내 확진자 현황이 어떻게 될지는 의문입니다.
국내 감염이 줄면서 중요하게 봐야할 것은 해외로 부터 유입되는 감염사례입니다. 해외 유입까지 완벽하게 관리할 수 있다면 국내 코로나를 종식시킬 수 있습니다. 해외유입확진자를 예측하여 미리 대비를 한다면 확실한 예방이 가능할 것 입니다.
그럼 시작해보도록 하겠습니다.
프로젝트 목표
해외유입확진자에 대한 시계열(Time-Series) 데이터를 사용하여 예측 모델을 만듭니다. 이를 통해 가까운 미래에 발생하는 해외유입 사례를 예측합니다. 14일의 미래값을 예측하는 것이 프로젝트의 목표입니다.
모델링에는 PyTorch 기반 LSTM 모델을 사용합니다. LSTM은 자연어 분야 딥러닝에서 많이 쓰이지만, 시계열 분석에도 활용됩니다.
활용 데이터 정의
예측 모델링에 사용할 Input Data는 2020년 1월 22일 부터 2020년 5월 5일까지의 총 105개의 관측치와 84개의 컬럼으로 구성된 데이터입니다. 데이터는 다음과 같이 구성됩니다.
- 핸드폰 로밍 데이터
- 해외 코로나 관련 크롤링된 뉴스 데이터
- 해외 국가별 코로나 확진자 데이터
- 코로나 관련 키워드로 검색한 구글 트랜드 지수
- 질병관리본부에서 크롤링한 해외유입확진자 데이터 (Target Feature)
변수 명 정의

- Date : 날짜(index)
- 국가코드_conf : 해당 국가의 일별 확진자 수
- 국가코드_roam : 해당 국가로 부터 한국으로 들어온 일별 로밍 이용자 수
- KR : 국내 일별 확진자 수 (지역사회)
- news : 코로나 관련 해외 뉴스 일별 갯수
- covid_tr : 'covid' 키워드로 검색한 구글 트렌드 지수
- coro_tr : 'corona' 키워드로 검색한 구글 트렌드 지수
※ 국가코드 : ISO-3166-1에 의한 2자리 알파벳 국가 명칭
이제 예측 분석에 들어가보도록 하겠습니다.
0. 패키지 로드
import torch
import os
import numpy as np
import pandas as pd
from tqdm import tqdm
import seaborn as sns
from pylab import rcParams
import matplotlib.pyplot as plt
from matplotlib import rc
from sklearn.preprocessing import MinMaxScaler, StandardScaler
from sklearn.metrics import mean_squared_error
from pandas.plotting import register_matplotlib_converters
from torch import nn, optim
%matplotlib inline
%config InlineBackend.figure_format='retina'
sns.set(style='whitegrid', palette='muted', font_scale=1.2)
HAPPY_COLORS_PALETTE = ["#01BEFE", "#FFDD00", "#FF7D00", "#FF006D", "#93D30C", "#8F00FF"]
sns.set_palette(sns.color_palette(HAPPY_COLORS_PALETTE))
rcParams['figure.figsize'] = 14, 10
register_matplotlib_converters()
RANDOM_SEED = 42
np.random.seed(RANDOM_SEED)
torch.manual_seed(RANDOM_SEED)
import warnings
warnings.filterwarnings('ignore')
from matplotlib import font_manager, rc
font_name = font_manager.FontProperties(fname="c:/Windows/Fonts/malgun.ttf").get_name()
rc('font', family=font_name)
1. 데이터 로드 및 전처리
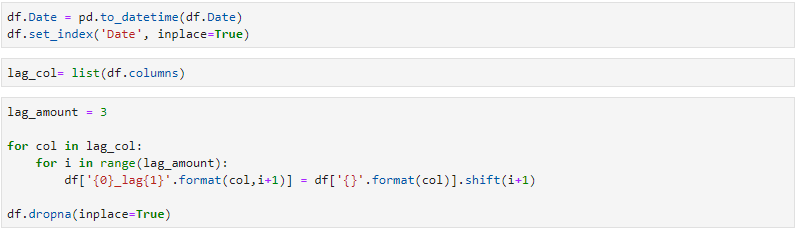
모든 변수에 대해 시차(Lag)변수를 생성해줍니다.
각 변수들에 3개의 시차 변수를 만들어 주고 Lag 생성으로 인한 na 값은 row를 통채로 날려줍니다.

위의 그래프는 해외유입확진자를 일일 별로 시각화해본 것입니다. 1월22일 부터 초기 해외유입의 경우 상당히 작은 값들이고 오히려 학습에 방해가 될 수 있다고 판단하여 lag변수를 생성한 후 결측치가 생성된 row들은 삭제를 했습니다.
따라서 lag변수를 각 3개씩 만들었기 때문에 NA값이 있는 3개의 row가 생성되었고 그 3개 row를 삭제합니다.
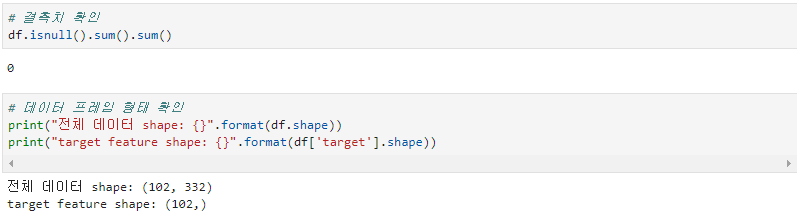
다음은 데이터의 결측치와 데이터 shape를 확인해줍니다. 102개의 row와 332개의 컬럼으로 구성되어있습니다.

X변수와 y변수를 구분해줍니다. target(해외유입확진자) 변수를 분리하여 y로 지정해주고 나머지 변수는 X로 지정해줍니다. test set의 사이즈는 14로 지정해줍니다. 보통 7:3 정도로 train / test set을 나누지만 2주의 예측값을 산출하는 것이 목표이고 데이터가 적기 때문에 14로 지정하였습니다.

다음은 X, y에 스케일링을 해줍니다. Scikit-learn의 MinMaxScaler를 사용합니다. 스케일된 데이터를 추후에 다시 inverse scale 해주기 위해 X 데이터와 y데이터 각각 스케일러를 만들어 적용해줍니다. 그 후에 train / test 셋을 구분합니다. 밑에 나올 lstm sequence를 만들어주기 위해 y데이터를 flatten()하여 차원을 줄여줍니다.


위의 함수는 모델 안에 들어갈 데이터를 시퀀스 형태로 만들어 주기 위한 함수입니다.

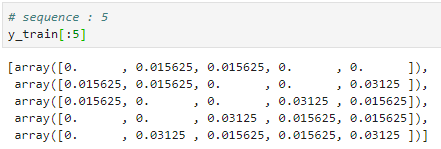
위의 예시는 함수를 사용하여 데이터를 시퀀스형태로 만든 모습입니다. 5개 씩 한 시퀀스로 묶었을 경우입니다. X_train을 보면 한 1개의 array에 5개의 데이터가 들어가 있습니다. 쉽게 말하자면 1월 22일 부터 1월 26일까지의 X 데이터가 하나로 묶여서 모델로 들어가는 구조입니다. 이러한 시퀀스 형태로 만드는 이유는 시계열 데이터의 순서를 학습시키기 위함입니다.

하지만 저는 시퀀스를 따로 만들지 않고 사용했습니다. 시퀀스를 만들지 않고 사용하려면 seq_length를 1로 주면됩니다.
목표했던 것은 14일 예측하는 것이었는데 시퀀스를 만들면 시퀀스를 만듦으로써 데이터 또한 더 필요하게 됩니다.
가지고 있는 데이터는 한정되어있기 때문에 시퀀스를 만들지 않고 사용하였습니다.

다음으로 PyTorch 모델에 데이터를 올리기 위해 torch.tensor로 변환해줍니다.
2. 모델 생성

이제 모델을 생성해보겠습니다. 모델은 상당히 간단합니다. 크게 LSTM과 Linear로 구성되어있고 num_layers로 레이어층의 갯수를 설정할 수 있도록 하였습니다. 데이터가 적고 딥러닝 모델의 크거나 깊지 않으므로 dropout은 따로 주지 않았습니다.
Training
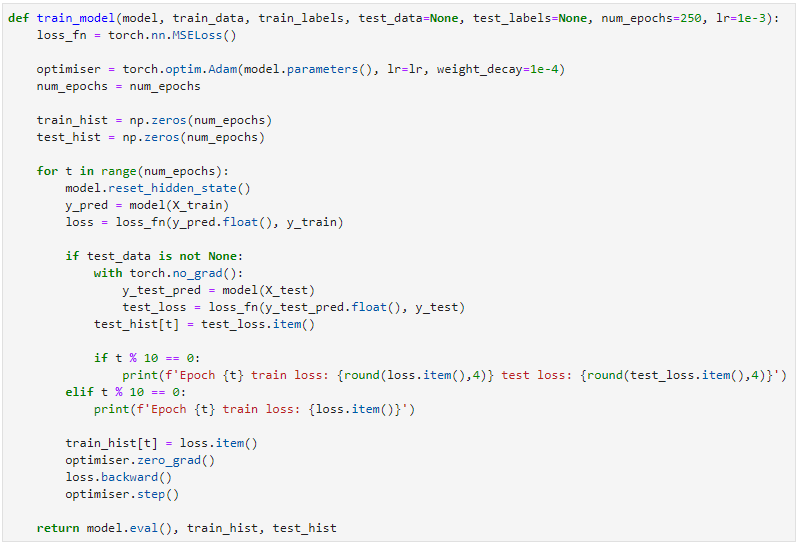
이제 모델을 훈련 시켜보겠습니다. epoch과 learning rate를 파라미터로 설정할 수 있게 하였습니다.
loss function으로는 MSELoss를 사용했고 optimizer로 Adam을 사용했습니다. optimizer에 weight_decay를 설정해주었습니다. 10 epoch 마다 train과 test의 loss를 출력하도록 하였습니다.

여러번의 시도 결과 파라미터를 위와같이 주었을 때 가장 괜찮은 결과가 나왔습니다. epoch 200으로 학습을 진행합니다.

학습 결과입니다. loss가 수렴하는 모습을 보면 상당히 비정상적인 것을 볼 수 있습니다. 우선 train보다 test의 loss가 더 낮습니다. 이것은 두가지 정도로 해석을 해볼 수 있는데요.
1) train data가 너무 어렵거나 test data가 너무 쉬울 경우에 train loss 보다 test loss가 낮게 나올 수 있다고 합니다.
2) 100여개 정도의 데이터를 가지고 딥러닝 모델을 돌렸으니 사실 정상적인 학습은 아니었습니다. 데이터의 수가 너무 적어서 위와같은 형태로 나온 것이라 생각합니다.
3. 일일 케이스 예측해보기
모델을 학습시켰으니 이제 예측을 해볼 차례입니다.

다음 코드를 통해 X_test 값을 모델에 넣어 예측값 preds를 산출해봅니다. 소수점의 결과값들이 나오는데 이건 위에서 데이터를 스케일링 해줬기 때문입니다.
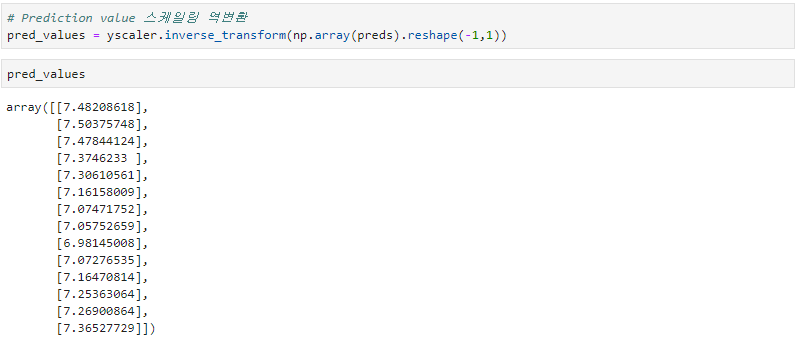
예측값을 스케일링을 역변환하여 결과를 확인해봅니다. 대략 6~7명 정도의 해외유입확진자가 나올 거라고 모델이 예측을 해줬습니다. 그럼 실제값과 한번 비교를 해보겠습니다.

실제 y값 'True'와 모델로 부터 나온 예측값 'Pred'로 구성된 score_table을 생성하였습니다. 저 값들은 4월 22일 부터 5월5일까지의 실제값과 예측값입니다. 눈으로 대략적으로 살펴보면 예측값이 거의 단일 값이라서 그런지 생각보다 잘 맞추지는 못하는 것 같습니다.

이번에는 평가지표로 성능을 살펴보겠습니다. MSE와 RMSE를 생성하였습니다 score는 실제값과 예측값의 차이가 작을 수록 100에 가까워지는 점수입니다. 이 모델은 81점 짜리 모델이군요 ㅠㅠ
MSE를 살펴봐도 9.2정도면 그렇게 잘 예측하지는 않는 것 같습니다.

실제값과 예측값을 전체그래프를 통해 시각화해봤습니다. 노란선이 실제값이고 빨간선이 예측값입니다. 실제 해외유입확진자의 경우에는 일일별 굴곡들이 있는 것을 볼 수 있지만 모델은 이러한 디테일까지는 잡지 못한 것 같습니다.

마지막으로 생성한 모델을 저장합니다. PyTorch의 모델 확장자 형식인 .pth로 저장해줍니다. 모델의 파일명은 사용한 파라미터와 점수를 넣어 어떤 모델이었는지 구분할 수 있도록 하였습니다.
4. 전체 데이터를 사용하여 미래 예측
마지막으로 전체 데이터를 사용하여 미래값을 산출해보도록 하겠습니다.

위에 했던 것과 동일하게 데이터를 전처리해줍니다. 대신 Train, Test를 나누는 것이 아닌 전체 데이터를 사용합니다.

DAYS_TO_PREDICT는 예측할 날짜의 수입니다. 저는 14일을 예측하는 것이 목표였기 때문에 14로 설정하였습니다.

14일 치의 미래 예측값입니다. 7명에서 0명까지 떨어지네요. 모델이 실제로 해외유입확진자의 감소를 학습을 한건지 아니면 딱히 예측에 대한 근거나 힘이 없어서 떨어질거라고 예측한건지는 알 수가 없습니다...

미래값들을 시각화해보았습니다. 감소하는 추세는 반영이 됬으나 정확한 값을 기대하기는 어려울 것 같습니다.
마지막으로 질병관리본부에서 발표한 해외유입확진자와 모델로 부터 나온 예측값을 비교해보겠습니다.

글을 작성하고 있는 오늘 11일까지의 해외유입확진자와 비교해봤을 때 정확하게 맞추지는 못하고 있네요... 정확하게 예측하는건 어려운일 같습니다. 실제의 급격한 증가 등은 반영하지 못하고 있습니다. 19일까지 예측을 했으니 나머지는 어떻게 될지 기다려 봐야 알겠군요.
완벽한 지식을 가지고 예측 모델을 만들어 본 것은 아니지만 재밌게 봐주셨으면 좋겠습니다! 부족한 글 봐주셔서 정말 감사합니다.
전체코드는 깃허브에서 확인하실 수 있습니다.
https://github.com/Hinterhalter/Post-COVID-19_modeling/blob/master/COVID19_Timeseries_LSTM.ipynb
Hinterhalter/Post-COVID-19_modeling
Contribute to Hinterhalter/Post-COVID-19_modeling development by creating an account on GitHub.
github.com
참고자료: https://www.curiousily.com/posts/time-series-forecasting-with-lstm-for-daily-coronavirus-cases/